Towards AI
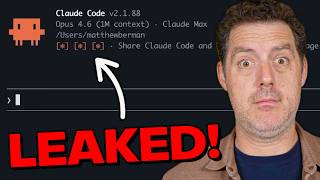
AI Labs Race to Build Enterprise Deployment Layer
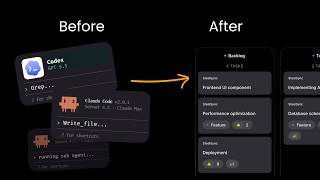
OpenAI and Anthropic partner with PE firms and consultancies to deploy AI in enterprises, addressing the adoption bottleneck beyond compute shortages amid explosive cloud growth (Google Cloud +63% to $20B).