Towards AI
8 Habits to Unlock Claude Code's Full Potential
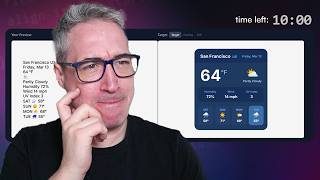
Transform Claude Code from smart autocomplete to shipping accelerator by treating CLAUDE.md as living memory, using /btw for side queries, Chrome extension for visual verification, /sandbox to cut 84% of prompts, critiquing plans like design reviews, running multi-sessions for TDD, and /clear between tasks.