#backend
Every summary, chronological. Filter by category, tag, or source from the rail.
Scaling Python: 9 Hidden Bottlenecks of Successful Projects
Successful projects face unique technical debt that only emerges at scale, specifically regarding database performance, memory management, and long-term maintainability.
5 Low-Effort Backend Configurations for Production Resilience
Improve backend stability and performance by implementing response compression, request timeouts, connection pooling, secret caching, and tiered rate limiting.
Preventing Silent Infrastructure Cost Leaks in Python Pipelines
A subtle bug in a Python data pipeline caused $80,000 in excess cloud costs due to inefficient resource handling; the fix required just four lines of code to implement proper connection management.
Stop Adding Indexes to Fix Slow Queries — You’re Quietly Killing Your Writes
Every index you add is a permanent tax on write performance. To maintain system health, you must audit for unused and redundant indexes, as these provide zero read benefit while slowing down every insert, update, and delete.
Defining the Coordination Boundary in Distributed Systems
Coordination libraries should strictly manage lease state and fencing, leaving external side effects, idempotency, and recovery logic to the application layer to avoid coupling and bloat.
5 Essential Database Patterns for Production-Ready Python Backends
Prevent catastrophic data loss and ensure system reliability by implementing soft deletes, audit trails, and robust database safety patterns before your first production incident.
Building Resilient SharePoint Delta Ingestion Pipelines
Avoid full-library scans by using the Microsoft Graph Delta API and SQL-based checkpointing, ensuring only changed files are processed and system state remains consistent during failures.
Scaling RAG Pipelines to 10M+ Documents with High Accuracy
To minimize hallucinations at scale, implement a multi-stage RAG pipeline that combines hybrid indexing, reciprocal rank fusion, and a strict 'retrieve, constrain, verify, abstain' workflow that forces the model to cite evidence or admit ignorance.
Architecting Durable AI Memory and Reliable Action Execution
To prevent AI context collapse and execution failures, implement a tri-tier memory architecture (Redis, PostgreSQL, pgvector) combined with relevance-based token management and Temporal-backed durable workflows.
Building Resilient Systems with Smart Retry Mechanisms
Retries are essential for handling transient failures in distributed systems, but naive implementations cause 'retry storms.' Use exponential backoff with jitter, ensure idempotency, and monitor retry metrics to maintain system stability.
Moving From Raw Logs to Observability Narratives
Logging is not the same as visibility. To debug production failures effectively, you must move beyond isolated log lines and implement request-based tracing that tells a coherent story of every execution.
8 Python Libraries for Building Scalable Systems
Scalability is not a late-stage concern; it is a design choice made by selecting the right libraries early to handle concurrency, data processing, and distributed task management.
Fixing RAG Hallucinations Through Better Retrieval Architecture
RAG failures are rarely LLM hallucinations; they are retrieval failures. To fix them, you must move beyond simple semantic search and implement robust document versioning, metadata filtering, and re-ranking.
Firebase as a Client-Side Launchpad for AI Agents
Firebase is evolving into a friction-free backend for AI agents by integrating directly into IDEs and AI coding tools, allowing developers to add persistence, auth, and SQL capabilities without leaving their development environment.
 Google Cloud Tech
Google Cloud TechChoosing Backend Infrastructure for AI-Driven Development
Upstash, Supabase, and Neon serve distinct architectural roles; choosing between them depends on whether you need a caching layer, a full-stack backend, or a cost-efficient, branchable Postgres database.
Implementing Request Scheduling and Preemption in NanoGPT
To move beyond FCFS processing in LLM inference, implement a priority-based scheduler that manages KV cache memory budgets through admission control and recompute-based preemption.
Django-Unfold: Modern Admin with Models, Filters, Actions, KPIs
Transform Django admin into a pro e-commerce dashboard using Unfold: custom sidebar nav, KPI cards, filters, badges, actions, and seeded data—all in a Colab-reproducible setup.
Token Bucket Fails at Window Boundaries—Use Sliding Window
Token bucket rate limiting lets clients burst 40 requests across a minute boundary despite 100/min limit; sliding window counters prevent this by tracking requests in the last N seconds from now, enforcing even distribution.
Skip Heavy Clean Architecture in Python Unless Scale Demands It
Over-applying clean architecture in Python FastAPI apps requires 7 changes for one field addition, killing velocity; Django's simple models need just 2 lines, proving less structure ships faster.
Fire-and-Forget Background Tasks: Python's 500ms Rule
Keep request-response under 500ms by decoupling acknowledgment (HTTP 202) from execution. Use reference registries for asyncio, FastAPI BackgroundTasks for light work, multiprocessing for CPU tasks, or Celery for persistent, scalable jobs.
Ditch preferred_username for Azure AD Guest Auth
Using preferred_username as identity anchor worked for employees but failed silently for all B2B guests, causing 403 errors post-launch. Anchor on oid instead for reliable identification.
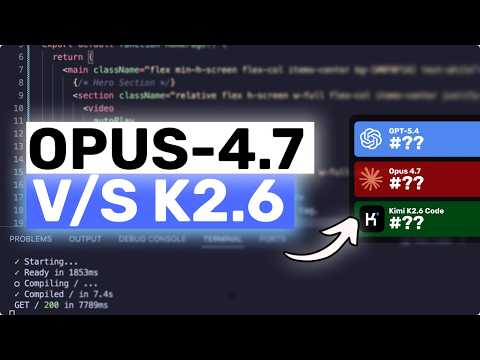
GPT-5.4 Best for Coding; Kimi K2.6 Tops Value vs Opus 4.7
GPT-5.4 leads in backend, debugging, planning, and reliability across tasks. Kimi K2.6 Code excels in frontend UI and offers superior speed/cost value. Opus 4.7 underperforms on messy backend work unless paired with Verdent's workflows.
 AICodeKing
AICodeKingGraphQL Fits AI Agents' Token Limits Perfectly
GraphQL's introspection, exact field selection, and types prevent token waste in AI agents, unlike REST which forces over-fetching and lacks runtime self-description.
Scale Stateless Backends by Broadcasting Client Updates
Horizontal scaling routes callbacks to replicas without client SSE/WebSocket connections, silently dropping updates—broadcast via Redis Pub/Sub so the owning replica delivers reliably.
Pure TypeScript Domains: Swap CRUD for Event Sourcing, Zero Rewrites
Use noDDDe's Decider pattern to build pure function-based aggregates decoupled from persistence—test without mocks and switch from SQL state storage to event sourcing by changing one config line.
Primeagen's Live SQL Bootcamp on boot.dev
Casey Muratori live-streams boot.dev's SQL course, building a PayPal clone hands-on from SELECT basics, while roasting GitHub outages and AI code horrors.
 The PrimeTime
The PrimeTimeJS Client for WooCommerce REST API CRUD Ops
Use @woocommerce/woocommerce-rest-api to GET, POST, PUT, DELETE WooCommerce data like products/orders via Axios promises; requires store URL, consumer key/secret.
Showing 30 of 32